



Executing condition monitoring on industrial PCs means that with proactive measures, OEMs and industrial users can increase the availability of their machines and equipment and keep downtimes to a minimum.
The basic prerequisite for monitoring, however, is profound knowledge about accessing the sensors of the individual hardware and peripherals. OEMs can save time and money if they opt for industry servers which already have application-ready monitoring and signaling functions integrated.
by Günther Dumsky, Global Product Line Manager Rackmount IPC, PICMG 1.x, BoxPCs, Kontron
Currently a great deal is being written about ‘Industry 4.0’, the future project which the federal government is pushing ahead as an integral part of its action plan for the German high-tech strategy. According to Industry 4.0, the economy is on the brink of a fourth industrial revolution in which so-called Cyber-Physical-Systems (CPS) take on an increasingly important role. It refers to all systems integrated in industrial processes where the aim is to have them networked both locally as well as factory-wide in the internet of things. This network would then give access to all the relevant data necessary for the development of intelligent monitoring functions and autonomous decision processes. It would make it possible to control, monitor and optimize all the value added networks in real time. Not only to increase the production output thanks to more efficient operations, but by continuous monitoring of key vital parameters of systems and peripherals, faults can be predicted and anticipatory maintenance carried out to avoid costly downtimes.
Similar to traditional IT servers, in terms of money the consequences of an industrial PC failure can be extremely drastic. While IT servers are, however, in the majority of cases running in air-conditioned rooms and are being monitored by IT administrators, industry PCs more often than not have to operate in harsh environments. To date, centralized monitoring by IT specialists is rare. So, unexpected failures with all their unpleasant consequences are inevitable because even the best hardware can fail at some point. For example, if the environmental temperature exceeds the permitted range, the fan becomes dirty in this raw industrial environment or a hard disk can no longer stand up to the vibrations in a machine hall.

Continuous monitoring of vital operating parameters, such as processor temperature, fan rotation speed, state of hard disk and system voltages means that possible failures can be detected at an early stage – also in an industrial environment – and suitable measures can be put into action in advance. Hard disk failures, which predominantly have mechanical causes, usually make themselves known in advance by, for example, the slow deterioration of the vital parameters. This deterioration includes an increasing number of read/write errors or defect sectors which can be read from the hard drives with help of the standardized Self-Monitoring, Analysis and Reporting Technology (S.M.A.R.T.). Even imminent failures of system and processor cooling fans announce themselves in advance with changing fan speeds or higher processor temperatures.
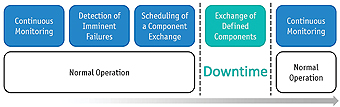
Monitoring these parameters makes it possible to predict such failures occurring and components can be purchased accordingly -plus exchanging them can be carried out during routine maintenance, so that expensive production downtimes can be avoided. Maintenance costs can easily be reduced by factor 10 to 100, provided that maintenance is carried out in advance. Taking on a forward-looking approach, which includes the continuous monitoring of all vital parameters would save the operator both time and money as well nerves. If OEMs are in a position to offer maintenance solutions like this then this closer cooperation with the customer results in a significant improvement in the after-sales relationship.
Appropriate solutions are to date scarce
Solutions which have been available in the market to date for permanent monitoring of industry servers are often connected to the sensors with dedicated hardware building blocks, which are an additional cost factor. Not every OEM is prepared to pay this additional cost and neither is the end-user. On the other hand, there is a large number of professional software-based remote management solutions for IT servers, which however are not tailored to the industrial server market, and are often oversized. Until now, searching for affordable solutions more or less always ended at software tools, which require profound knowledge of the hardware and of

all the monitored hardware components as well as of all the sensors and the access to sensor data. OEMs and end-users, however, want simple tools, which present the required information as easily and conveniently as possible. And they want this, if possible, available on all communications channels, which can be easily integrated into existing infrastructures and work processes. What’s required are individually configurable notification methods such as e-mail or SMS directly to the service technician. Particularly in demand from OEMs are network protocols such as SNMP or the web service interface SOAP (Simple Object Access Protocol). This allows vital parameters to be passed to a centralized monitoring server, which can take on the monitoring of multiple systems. Therefore, a simple, inexpensive and efficient monitoring system is required which provides significant benefits with a minimum of effort.
Remote management for industrial applications
A solution which fits this bill of OEM requirements is available from Kontron. The PC Condition Monitoring PCCM is a software solution which takes care of permanent condition monitoring of industry servers. The PCCM is available for Kontron’s KISS server family but other product families can also be equipped with this.
The permanent condition monitoring system has been designed for ease of use and inexpensive application per installation. It directly accesses the corresponding condition parameters of the server components.
Service technicians and administrators can receive individually parametrizable condition monitoring alerts by a method of their choice i.e. SMS, e-mail, SNMP, Windows News Service or on-site as acoustic and/or optical signals. If required, the data can be stored in an archive that can be viewed both locally and remotely, as remote access of the system is also possible.
A SOAP web service is also implemented to enable the connection of customer-specific maintenance systems.
Additionally via the parallel interface, hard-wired signaling can be carried out.
Secure implementation
In contrast to a wide range of condition monitoring tools, which are based on the industry standard ACPI (Advanced Configuration and Power Interface), the PCCM accesses the data of the sensors and hardware directly via its own API. This means that the PCCM works especially reliably without any influence from the software or
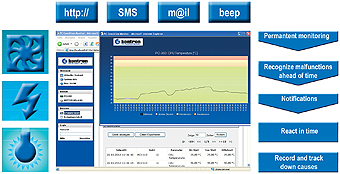
driver. The OEM’s customer, or the OEM himself, experiences a significant increase in terms of maintenance convenience without having to be in possession of any in-depth knowledge about the hardware and without having any additional effort. The measurable condition parameters include system voltages, temperatures of the processors, chip set or hard disk as well as rotation speed of processor, chassis and power supply fans. Hard disk status is read via the S.M.A.R.T.-interface. Alternatively, monitoring entire RAID subsystems is possible. Even supply voltages and the availability of redundant power supplies can be measured with the PCCM.
What the user sees
In addition to alerting via SMS or e-mail, the condition data can be displayed using a standard web browser at the system technician’s workplace. Condition diagnosis is an intuitive process with its green-amber-red traffic light system. Also the parameters for triggering and resetting threshold values as well as time delays for noisy or peak-prone parameters can be individually set via the web interface. Condition statistics for long-term diagnoses over the complete lifecycle are also stored. The minimum, maximum or average values of any statistics can be stored for any period of collection time. Different storage intervals within and outside of the normal operating range can help to reduce the variety of data without any loss of precision. For external analysis, the data can be exported to the open CSV format which makes importing it into various data bases an easy task.
Flexible expandability
Owing to the modular application structure, apart from the condition parameters, which are supplied via the various embedded hardware components, vendor-specific measuring data can be integrated. As an example, the prompting of external shock and humidity sensors or other peripherals can be carried out. And even when it comes to configuring threshold values for alerting, customers are not out on a limb. Kontron not only can reap from and share its vast experience in this field but can, if necessary, carry out the configuration before the product is shipped.
Author: Günther Dumsky is Global Product Line Manager Rackmount IPC, PICMG 1.x, BoxPCs at Kontron in Eching.
www.kontron.com