


Serial RapidIO (SRIO) support is more and more prevalent in processors and chip sets from manufacturers such as Freescale and furthermore, SRIO – along with 10 Gigabit Ethernet – is becoming increasingly interesting as a system / board interconnect. Which level of performance do current systems actually offer though? Kontron has tried and tested SRIO performance under MicroTCA system conditions.

Authors:
Matthias Greulich, Software Design Engineer
Claudia Bestler, Business Development and Product Marketing
Avionic systems in the aerospace industry, radar systems, sonars and other digital resonance methods in medical technology, in cellular mobile measuring technology and digital image processing systems have to deliver ever more accurate and precise results. Methods to improve these systems are based on new processes and algorithms, which in turn require even more precise and increasingly faster data delivery to raise the systems’ performance and quality level. For processing and evaluating this raw data, computers with increasing higher levels of computing power are available. Choosing the right interfaces for data transmission is therefore of utmost importance. In systems like this, board-to-board communication using Serial Switched Fabrics like 10 Gigabit Ethernet or SRIO is recommendable. Both offer future-proof performance at nominal data rates of 10 Gbit/s or 12.5 Gbit/s for SRIO (3.125 Gbaud x 4 lanes). However, the transmission methods do show different results in terms of the effective data rates.
Different types of effectiveness
The difference between nominal and effective data transfer rates is predominantly a matter of latency and jitter factors. During the development of SRIO, special attention was paid on keeping any disturbing influencing factors to an absolute minimum. In order to reduce the number of interrupts, SRIO offers the corresponding Quality-of-Services: SRIO can prioritize data to significantly improve the performance of systems running several processors parallel to each other. Also, every SRIO endpoint can act as a “master” or “slave” during, for example, I/O logical operations (shared memory) or message operations (doorbell, messages). In this way, the “master” can directly initiate writing and reading processes in the memory of the “slave”, which reduces the total number of interrupts in the system and positively reflects on the performance of the whole system. Protection from transfer errors is also provided by the built-in, specified error recognition and correction on the hardware level: SRIO transmits the clock signal together with the data stream, which additionally reduces latency. SRIO also has a significantly smaller overhead than 10 Gigabit Ethernet. In a package size of 64 bytes on 10 Gigabit Ethernet for example, about a third of the data is assigned to the overhead. The data transfer rate is in effect only about 66%. At 64 bytes, SRIO on the other hand offers an effective data transfer rate of 95% and with that – and due to the small overhead – delivers performance which is 50% higher. To reduce the overhead, SRIO uses a leaner layer structure. In contrast to the ANSI Layer Standard, which recommends seven layers for data interfaces, SRIO manages with just three layers: the Logical Layer, the Transport Layer and the Physical Layer. The ID which is used and the package-oriented protocol of SRIO has a direct effect on the application software, as the required operations, like, for instance, maintenance, write or read transactions can be carried out without a larger overhead. After the SRIO enumeration (= system recognition: SRIO Switch Routing Table Configuration and the device ID allocation to participating SRIO agents) via the SRIO host and the setting up of necessary resources (i.e. SRIO endpoint ATMUs = Address Translations and Mapping Unit) the data exchange can be executed as I/O logic (NREAD, NWRITE) and/or message operations.
Measurable differences in performance
In order to document and quantify SRIO’s performance, Kontron carried out tests on the MicroTCA system Kontron OM6040 (see figure 1). The MicroTCA system was equipped with two Kontron AM4100 AMC modules with Freescale dual-core MPC8641D processors as SRIO host (MicroTCA slot 1) and agent (MicroTCA slot 4) along with a SRIO MicroTCA Controller Hub (MCH) with two SRIO switches. As an operating system (RTOS), Wind River VxWorks 6.6 with the Kontron Board Support Package (BSP) for the AM4100 / AM4101 and a corresponding test application were used.
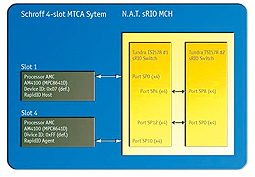
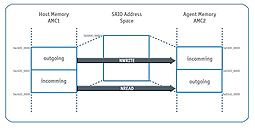
In this configuration the (DMA supported) data transfer rates of NWRITE (host writes on agent) and NREAD (host reads from agent) were measured (see figure 2). During the writing process from the memory of the host CPU to the agent CPU via SRIO, a user data rate of 6.44 Gbits/s was reached. During the reading process in the opposite direction, data was transferred via SRIO at a rate of 7.7 Gbits/s.
In a similar test carried out by the University of Oklahoma, 10 Gigabit Ethernet with a PDU size of 64 bytes only achieved 3.3 Gbit/s (Hernan A. Suarez: Recent Study on High Speed Serial Links for Multifunction Digital Array Receivers and Processors, 2008: http://arrc.ou.edu/~rockee//RIO/arrc-1p-SRIO_Aurora-Hernan.pdf). For smaller data packages SRIO offers about double the capacity for data transfer in comparison to 10 Gigabit Ethernet. Only with data packages (PDUs = Protocol Data Units) of above 1,000 bytes could 10 Gigabit Ethernet offer better performance (Source: RapidIO / see figure 3). In a real system, the effective data rate not only depends on the share/percentage of user data in a PDU. Although, the larger the size of the user data, the more the effective data transfer rate improves (as the package overhead is smaller). When both processors are writing and reading at both ends of the chain, this requires the processing of the packages with the related interrupts. Additionally, effects due to latency and jitter can slow down the effective data rate.
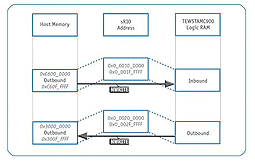
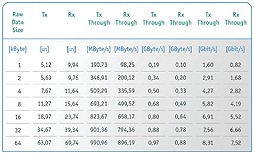
During an evaluation using a XILINX LogiCORE IP Serial RapidIO v4.4-SRIO endpoint based on XILINX Virtex-5 FPGA with a Tews Technologies TAMC900 (see figure 4) an even higher transfer rate was measured. The writing process over the whole chain from the host memory of the Kontron AM4100 via SRIO to the memory of TAMC900 (logic RAM) happened at a rate of 8.31 Gbit/s, with 64 kByte raw data size. In the opposite direction, the writing process was carried out at a data rate of 7.52 Gbit/s.
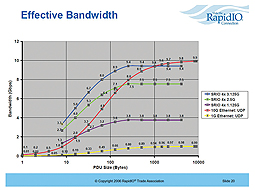
This series of measurements for different raw data sizes between 1 kByte and 64 kByte shows the real changes. (Figure 5) SRIO is also especially recommendable for applications which require continuous data transmission, as is the case in applications such as measuring sensors, radar or telecommunication systems.
The future development of SRIO will also see – among many other things – an acceleration of transfer rates (5 Gbaud, 6.25 Gbaud) to meet the growing demands in these areas.
Flexible system architecture
To bring the benefits of SRIO to developers, Kontron not only offers solutions on CPU boards but also at system level. One of the many configuration possibilities is the MicroTCA system Kontron OM6040 Compact with built-in Kontron AM4100 CPU board and MCH, as used in this benchmark. In this system, a Kontron AM4100 – as an SRIO host – is responsible for the management of SRIO components, the Memory Controller Hub (MCH) takes care of the physical connections between the components. Communication takes place either via ×1 or ×4 lanes. Both star and ring as well as (full-) mesh topologies are supported.
Computing power on a particularly high level can be attained, for example, by hooking up 12 or more AMC boards together via SRIO with several switches, thus creating a powerful Switched Fabric system. New solution concepts are moving towards replacing DSP boards with multicore CPU boards, enabling system designs from several AM4100 CPU boards. An attractive aspect of this is the fact that Kontron AM4100 boards have an integrated 128 bit AltiVec vector unit, which ensures minimal cache pollution when processing huge amounts of data. The Kontron AM4100 is predestined for telecommunication infrastructure systems for TEMs (Telecommunication Equipment Manufacturers) or enterprise-wide data communication systems. Further application areas for the PowerPC processor module are in medical and industrial image processing and in the aerospace industry. The four Gigabit Ethernet interfaces offer highest data transfer rates thanks to the latest technologies it has implemented for checksum acceleration of TCP and UDP, QoS support and packet-header manipulation.
As an alternative to SRIO, PCI Express interfaces are possible which means the board can be used in a wide range of configurations. If both PCI Express and SRIO are required in an application, the Kontron AM4101 is an ideal choice.
As both interfaces run via the different ports of the AMC Fat Pipes Region (according to SCOPE Alliance), the AM4101 support both PCI Express and SRIO. If OEMs need a complete system, integrated components are available according to customer requirements. Kontron MicroTCA systems support all common data interfaces (PCI Express, GbE, SRIO etc.) and in doing this offer developers the freedom of choice in system development.
User data to PDU
So that data, whether in form of files or memory content – can be transferred via e.g. SRIO or Ethernet, it has to be divided into data packages with defined sizes. Every user data package receives a so-called overhead which contains additional, protocol-specific administration information (i.e. recipient, checksum for error correction etc.). In total this adds up to the so-called PDU = Protocol Data Unit. The higher the ratio of user data to the overhead, the more efficient the data transfer rate will be. Having said that, the data transfer rate cannot be indefinitely maximized by enlarging the amount of user data per PDU. When user data packages are too large, just single errors in data packages can lead to disproportionately long delays in the data flow. Sequential “filling” of data packages can also cause delays in CPU processing, as wait states can occur.
Kontron OM6040 Compact
SRIO performance was tested on the MicroTCA system, Kontron OM6040 Compact, this is a five-slot entry level platform developing small, compact and highly-integrated, multi-processor systems on MicroTCA basis. Application areas are telecommunication applications, triple play, defense, public security, avionics, image and video processing systems in medical technology or industrial quality management. The compact system (3U height, 250 mm depth and 156 mm width) is designed to accommodate a full-size MicroTCA Carrier Hub (MCH) and up to four Advanced Mezzanine Cards (AMC) including power supply and fan and is available in different basic configurations, with combined MCH and AMCs and with pre-installed operating system. The OM6040 offers a single star backplane for SRIO, GbE and PCI Express along with MicroTCA power management. Power supply is carried out via the backplane, so that MicroTCA power modules are no longer necessary, saving costs and time. The Memory Controller Hub is equipped with a GbE and PCI Express/SRIO switch. SAS and SATA are also available on the backplane. The design of the OM6040 can be adapted individually according to requirements.
www.kontron.com