



Today’s graphics processors are highly programmable, massively parallel compute engines. With the development of open, industry standards, parallel programming languages such as OpenCL™ and the continued evolution of heterogeneous computing, general-purpose graphics processing units (GPGPUs) offer exciting new capabilities for the embedded market.
GPGPU Challenges
What makes GPGPU computing so enticing is the availability of extreme floating-point performance in cost-effective GPUs. In order to benefit from these performance gains, embedded systems need to meet three more challenges: lower power consumption, open standards, and parallel algorithms.
Low power consumption is one of these challenges because embedded applications typically have more modest thresholds for TDP. They are furthermore faced with size, weight, and power (SWaP) constraints. Portable ultra-sound machines for example benefit from small size, yet demand high-performance compute capabilities for real-time imaging. GPGPU offers new compute capabilities within limited power budgets for telecom infrastructure. Many defense and aerospace applications (e.g., sonar, radar, video surveillance) require high-performance compute capabilities delivered in embedded form factors. To meet the growing demand for embedded GPGPU, the AMD Radeon E6760 Embedded GPU delivers 16.5 GFLOPs/W at a modest TDP of about 35W.
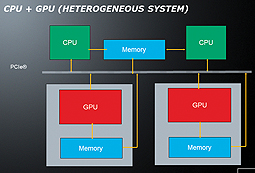
Heterogeneous Computing and OpenCL
To easily gain access to these performance gains OpenCL provides an open standard that enables parallel programming of GPUs (and other processors like CPUs, FPGAs, Cell, etc.). It is created by an industry consortium that includes many chip vendors, software companies, and research organizations. As it has matured, it has become the API of choice for code that is portable across different hardware and also different operating systems. This section discusses how OpenCL can be used for programming GPUs.
OpenCL Kernel
GPUs are extremely good at parallel processing, especially at doing similar computations on lots of data (also called data-parallel computations). We will use a very simple example to illustrate our point – a simple element-wise addition of two arrays a and b with the result written to another array c. Instead of adding one pair of elements at a time, as happens in CPU code, we can use OpenCL to do many additions in parallel on the GPU. The following table is a typical code snippet to do the addition on a single-core CPU, which looks very similar to the OpenCL kernel that will do the same addition on GPU.
CPU code OpenCL kernel code
for (int i = 0; i < sizeOfArray; i++) void kernel_foo(… … …)
{ {
c[i] = a[i] + b[i]; int i = get_global_id(0);
} c[i] = a[i] + b[i];
The operation for each item i is called a work-item. Conceptually, all work-items in a kernel are executed in parallel – we cannot tell if work-item i=x is physically executed before, at the same time, or after another work-item i=y. (However, we know that on GPUs, hundreds and even thousands of work-items can be in the midst of execution at any time.)
OpenCL provides us a way of grouping batches of work-items together into work-groups. In general, work-items cannot synchronize or exchange data with each other, but work-items belonging to the same work-group can. This allows us to write OpenCL kernels that are much more sophisticated than this example. Advanced examples are beyond the scope of this paper; however, there are plenty of tutorials available in the web that show advanced usage OpenCL kernel features.
OpenCL Host Program
Until now, we have talked about the code that will execute on the GPU. But first we will have to write a host program (CPU code) to control and use the GPU. It will find and initialize the GPU(s), send data and the kernel code to the GPU, instruct the GPU to start execution and know when the results are ready, and read back the results from the GPU.
OpenCL makes it easy for multiple implementations of OpenCL to co-exist on the same machine. For example, you can have one implementation that targets the CPU, another for the GPU(s), and yet another for other accelerators that may be on board.
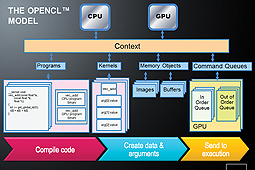
So, the first step in our OpenCL program has to be to find out how many platforms (implementations) are present on the current machine and choose one from them.
Within a platform, we will create a context (typically one, but we can create more for advanced usage). We can think of the context as a somewhat self-contained universe that contains the rest of the OpenCL resources. All of the following steps will take place specific to the context we create.
Next we query and retrieve the OpenCL devices present in this context – in our case, GPUs. We will also need to compile and build the OpenCL program (one or more kernels) for execution on the chosen devices.
We will also create OpenCL buffers that will store our data before and after GPU execution. For the addition kernel example, we will create three buffers oa, ob, and oc corresponding to the arrays a, b, and c.
Now that we have initialized the GPU and the code that will be executed on the GPU, we are ready to send commands to the GPU (send data, execute kernel, retrieve results, etc.). For efficiency reasons, it makes sense for the host (CPU) program to issue those command calls in an asynchronous (non-blocking) manner. That is, the host program should be able to submit a command to the GPU (for example, data transfer) and not have to wait for the action (data transfer) to be completed. This way, the host can move on to do other things, including sending other commands to the GPU.
OpenCL provides a nice construct to submit commands to the GPU: the command queue. For ease of use, there are both blocking and non-blocking variants for a variety of commands that can be submitted to the command queue. In addition, there are mechanisms to query whether a command (or an event) has completed, and ways for the host program to wait until all preceding OpenCL commands have finished execution. Depending on the properties of the command queue, the submitted commands may be executed either in order of submission or out of order.
All the steps we have performed on the host program until now are initialization activities towards setting up the GPU and preparing it to execute one or more programs. We have found a platform, created a context, initialized a device and one or more kernels, and created buffers and a command queue. For most use cases, we need to perform these steps just once, and then we can move on to executing the code on the GPU.
First, we will send the data in arrays a and b to the corresponding OpenCL buffers we created earlier. To be more specific, we will submit (or queue) commands to start the data transfers to the command queue. Second, we will set up the arguments the OpenCL kernel will use when it is executed. For the example using the addition kernel, we will bind the OpenCL buffers oa, ob, and oc to the kernel parameters a, b, and c.
Next, we will submit the action to execute the kernel. One critical piece of information we need to give at this point is how many items the addition kernel needs to work on. That is, we need to provide the total number of work-items.
In our example, the array sizes are sizeOfArray, so that will be the total number of work-items. After the kernel submission, we submit a command to read back from the OpenCL buffer oc to the array c. Assuming we submitted the previous calls to the command queue in a non-blocking fashion, we will need to make a call to wait until all submitted actions on the command queue are finished, at which point the correct result will reside on the target array c.
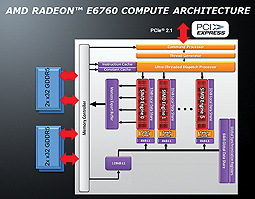
• TeraScale 2 architecture delivering 576GFLOPs SP (peak)
• Full hardware implementation of DirectCompute11, OpenCL 1.0, Shader Model 5.0
• Ultra threaded dispatch processor with instruction cache
• 6 SIMD engines (MPMD)
• Each SIMD engine consists of 16 Stream Cores (SC), Stream core = thread processor
• Each SC consists of 5 Processing Elements (PE)
• 6 SIMD * 16 SC * 5 PE = 480 PEs (or shaders)
• 64KB global data share (GDS) shared by SIMDs and accessible by host CPU.
• 128K L2 cache, dual-channel 128-bit GDDR5 memory interface
• GDDR5 memory controller
• EDC (error detection code) provides CRC checks on GDRR5 data transfers
• GDDR5 link temperature compensation, link retraining
• Architecture supports atomic operations, write coalesces, semaphores, barrier synchronization etc.
Conclusion
An understanding of OpenCL is the key for widespread adoption of GPGPU technologies
in the embedded market. Many algorithms map well to GPGPU architectures and show compelling performance gains compared to traditional multi-core CPU implementations. GPGPUs deliver compelling GFLOPs per watt with attractive GFLOPs per cost to enable new capabilities for size, weight, and power-constrained embedded applications.
Authors:

Peter Mandl is Senior Product Marketing Manager, Embedded Client Business at Advanced Micro Devices, Inc.

Udeepta Bordoloi is Senior Member Technical Staff, Embedded Client Business Compute Application Software at Advanced Micro Devices, Inc.
1 OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos